NVIDIA DGX ™ A100 ist das universelle System für alle AI-Workloads und bietet beispiellose Rechendichte, Leistung und Flexibilität im weltweit ersten 5 petaFLOPS AI-System. NVIDIA DGX A100 verfügt über den weltweit fortschrittlichsten Beschleuniger, die NVIDIA A100 Tensor Core-GPU, mit der Unternehmen Schulungen, Schlussfolgerungen und Analysen in einer einheitlichen, einfach zu implementierenden AI-Infrastruktur zusammenfassen können, die den direkten Zugriff auf NVIDIA AI-Experten umfasst.
Mit 5 petaFLOPS KI-Leistung, einer extrem hohen NVLink Bandbreite und der feinkörnigen Zuweisung von Rechenleistung durch die Multi-Instanz-Grafikprozessorfähigkeit ist die NVIDIA DGX™ A100 für alle KI-Arbeitslasten hervorragend geeignet. Von der Analyse über das Training bis hin zum Inferencing setzt die NVIDIA DGX™ A100 neue Maßstäbe.
Im Rahmen der Elite Partnerschaft mit NVIDIA bietet DELTA für einen begrenzten Zeitraum Tests auf der NVIDIA DGX™ A100 via Remotezugang an. Wenn Sie an einem Test Interesse haben und entsprechende Projekte planen, können wir Sie für einen Test einplanen. Bitte füllen Sie das Anfrageformular für einen kostenlosen NVIDIA DGX™ A100 Benchmark aus oder schicken Sie uns eine E-Mail. Zwecks Speicherung und Verarbeitung ihrer Testdaten stehen unterschiedliche Storage Lösungen bereit, die ihren Wünschen entsprechend in die Testumgebung via HDR InfiniBand eingebunden werden können. Natürlich nehmen wir auch gerne eine individuelle Softwarekonfiguration vor.
Falls die NVIDIA DGX™ A100 nicht in Ihr Budget passen sollte, können wir Ihnen nach Rücksprache auch andere Systeme aus unserem Portfolio für einen Remote Zugang zur Verfügung stellen. Bitte schicken Sie uns eine E-Mail mit ihren Projektdaten. Wir melden uns dann bei Ihnen, ob wir ein entsprechendes System für Testzwecke bereitstellen können.
Bereitstellung der Infrastruktur und operatives Skalieren der KI
Verkürzung der Zeit für Erkenntnisse und Beschleunigung der Kapitalrendite der KI
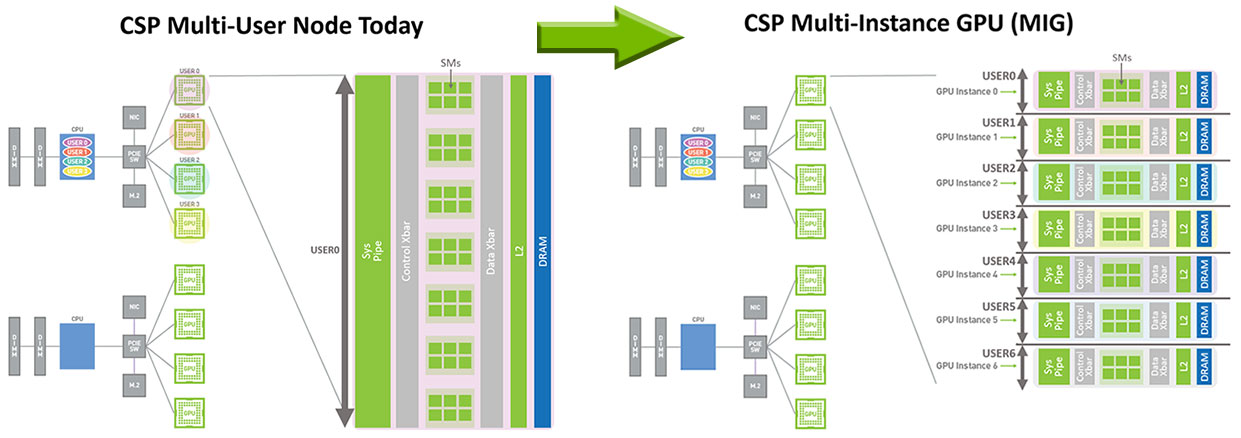
FUNKTIONSWEISE DER MULTI-INSTANCE GPU (MIG) TECHNOLOGIE
Ohne MIG konkurrieren verschiedene Aufgaben, die auf demselben Grafikprozessor ausgeführt werden, wie unterschiedliche KI-Inferenzanforderungen, um dieselben Ressourcen wie beispielsweise die Speicherbandbreite. Durch eine Aufgabe, die mehr Speicherbandbreite beansprucht, steht für andere Aufgaben weniger zur Verfügung, sodass mehrere Aufgaben ihre Latenz-Zielwerte verfehlen.
Mit MIG werden Aufgaben gleichzeitig in verschiedenen Instanzen ausgeführt, jeweils mit dedizierten Ressourcen für Rechenleistung, Arbeitsspeicher und Speicherbandbreite, was zu einer vorhersehbaren Leistung mit hoher Servicequalität und maximaler GPU-Auslastung führt.
Eine NVIDIA A100 Tensor Core GPU kann in verschiedene MIG-Instanzen aufgeteilt werden. Ein Administrator könnte beispielsweise zwei Instanzen mit je 20 GB Speicher oder drei Instanzen mit 10 GB oder sieben Instanzen mit 5 GB erstellen. Oder eine beliebige Kombination davon. Auf diese Weise können Systemadministratoren für unterschiedliche Arten von Workloads Grafikprozessoren mit der richtigen Größe bereitstellen.
MIG-Instanzen können auch dynamisch neu konfiguriert werden, sodass Administratoren die GPU-Ressourcen an wechselnde Nutzer- und Geschäftsanforderungen anpassen können. Sieben MIG-Instanzen können z. B. tagsüber zur Inferenz mit geringem Durchsatz verwendet werden und für das Deep-Learning-Training in der Nacht zu einer großen MIG-Instanz umkonfiguriert werden.
GAME CHANGING PERFORMANCE
Analytics
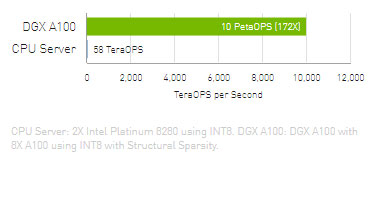
Training
Inference
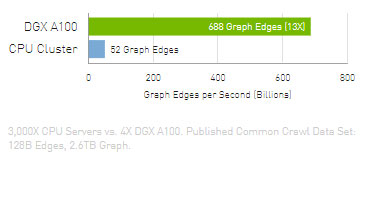
PageRank
NLP: BERT-Large
Peak Compute
Faster Analytics Means Deeper Insights to Fuel AI Development
Faster Training Enables the Most Advanced AI Models
Faster Inference Increases ROI Through Maximized System Utilization
MIG Architektur
DGX im Vergleich
Modell
NVIDIA DGX™ A100 640GB
NVIDIA DGX Station™ A100 320GB
GPUs
8x NVIDIA A100 Tensor Core GPU (SXM4)
4x NVIDIA A100 Tensor Core GPU (SXM4)
Architecture
7nm (Release 2020)
7nm (Release 2020)
GPU Memory pro System
640 GB (8x 80GB)
320 GB (4x 80GB)
Anbindung an CPU
PCIe 4.0 x16 (64 GB/s)
PCIe 4.0 x16 (64 GB/s)
Interconnect GPUs
NVIDIA® NVLink® (600 GB/s)
NVIDIA® NVLink® (200 GB/s)
Performance*
5 petaFLOPS
2.5 petaFLOPS
NVIDIA CUDA® Cores (FP32)
55.296
27.648
NVIDIA CUDA® Cores (FP64)
27.246
13.632
Neu: NVIDIA Tensor Cores (TF32)
3.456
1.728
Peak TF32 Tensor TFLOPS
1248 / 2496 *
624 / 1248 *
Peak FP16 TFLOPS with FP32 Accum.
2496 / 4992 *
1248 / 2496 *
Multi Instance GPU support
ja
ja
CPU
2x AMD EPYC 7742 insgesamt 128 Kerne, 2.25 GHz
1x AMD EPYC 7742 64 Kerne, 2.25 GHz
System Memory
2.0 TB DDR4
512 GB DDR4
Network InfiniBand / Ethernet
8x 200G HDR | 200 GbE
--
Network Ethernet
2x Dual Port 200 GbE
2x 10G GbE
Storage OS
2x 1.92 TB NVMe SSD
1.92 TB NVMe SSD
Storage Data
Total 30 TB NVMe SSD
Total 7.68 TB NVMe SSD
Software
Ubuntu Linux Red Hat Linux
Ubuntu Linux Red Hat Linux
Gewicht
123 kg
43 kg
Bauform
6U / Tiefe 897 mm
Tower mit Wasserkühlung
Temperaturbereich
5 – 30°C
10 – 30 °C
Maximum Power Usage
6.5 kW
1.5 kW
* Effective TOPS / TFLOPS using the new Sparsity feature.
Noch unentschlossen? Lassen Sie sich von der Performance der DGX A100 auf unserem Testgerät überzeugen!
Haben Sie Fragen zu der NVIDIA DGX™ A100 oder weitere Fragen zu den NVIDIA Produkten? Wir helfen Ihnen gerne weiter. Rufen Sie uns an, schicken Sie eine Mail oder nutzen Sie uner Anfrageformular: NVIDIA DGX Anfrage