Um Ihnen die Funktionen unseres Online-Shops uneingeschränkt anbieten zu können setzen wir Cookies ein. Weitere Informationen
NVIDIA DGX™ B300 ist eine einheitliche KI-Plattform für Pipelines von der Entwicklung bis zur Bereitstellung in Unternehmen jeglicher Größe und in jeder Phase ihrer KI-Reise.
Ausgestattet mit acht NVIDIA B300 Tensor Core-GPUs, die über NVIDIA® NVLink®der fünften Generation miteinander verbunden sind, bietet DGX B300 eine bahnbrechende Leistung mit der 3-fachen Trainingsleistung und der 25-fachen Inferenzleistung der Vorgängergenerationen. Durch die Nutzung der NVIDIA Blackwell-GPU-Architektur kann DGX B300 diverse Workloads bewältigen, einschließlich umfangreicher Sprachmodelle, Empfehlungssysteme und Chatbots, und ist damit ideal für Unternehmen geeignet, die ihre KI-Transformation beschleunigen möchten.
Kontakt aufnehmen / Preis anfragen:
NVIDIA DGX B300 | NVIDIA DGX B200 | NVIDIA DGX H200 | NVIDIA DGX H100 | |
| GPU | 8x NVIDIA Blackwell Ultra Tensor Core GPUs | 8x NVIDIA Blackwell Tensor Core GPUs | 8x NVIDIA Hopper Tensor Core GPUs | 8x NVIDIA Hopper Tensor Core GPUs |
| GPU Memory | 2,304GB total (8x 288GB) HBM3e | 1,440GB total (8x 180GB) HBM3e | 1,128GB total (8x 141GB) HBM3e | 640GB total (8x 80GB) HBM3 |
| Performance | 72 petaFLOPS training and 144 petaFLOPS inference | 72 petaFLOPS training and 144 petaFLOPS inference | 32 petaFLOPS FP8 | 32 petaFLOPS FP8 |
| NVIDIA® NVSwitch™ | 2x | 2x | 4x | 4x |
| System Power Usage | ~15.1kW max | ~14.3kW max | ~10.2kW max | ~10.2kW max |
| CPU | 2 Intel® Xeon® Platinum 6776P Processors | 2 Intel® Xeon® Platinum 8570 Processors 112 Cores total, 2.10 GHz (Base), 4.00 GHz (Max Boost) | 2 Intel® Xeon® Platinum 8480C Processors 112 Cores total, 2.00 GHz (Base), 3.80 GHz (Max Boost) | 2 Intel® Xeon® Platinum 8480C Processors 112 Cores total, 2.00 GHz (Base), 3.80 GHz (Max Boost) |
| System Memory | 2TB, max. 4TB | 2TB, max. 4TB | 2TB | 2TB |
| Networking | 8x OSFP ports serving 8x single-port NVIDIA ConnectX-8 VPI 2x dual-port QSFP112 NVIDIA BlueField-3 DPU | 4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 VPI 2x dual-port QSFP112 NVIDIA BlueField-3 DPU | 4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 VPI 2x dual-port QSFP112 NVIDIA ConnectX-7 VPI | 4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 VPI 2x dual-port QSFP112 NVIDIA ConnectX-7 VPI |
| Management Network | 1Gb/s onboard NIC with RJ45 | 10Gb/s onboard NIC with RJ45 | 10Gb/s onboard NIC with RJ45 100Gb/s dual-port ethernet NIC Host baseboard management controller (BMC) with RJ45 | 10Gb/s onboard NIC with RJ45 100Gb/s dual-port ethernet NIC Host baseboard management controller (BMC) with RJ45 |
| Storage | OS:2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe E1.S | OS:2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 | OS:2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 | OS:2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 |
| Software | NVIDIA AI Enterprise – Optimized AI Software NVIDIA Base Command – Orchestration, Scheduling, and Cluster Management DGX OS / Ubuntu – Operating System | NVIDIA AI Enterprise – Optimized AI Software NVIDIA Base Command – Orchestration, Scheduling, and Cluster Management DGX OS / Ubuntu – Operating System | NVIDIA AI Enterprise – Optimized AI Software NVIDIA Base Command – Orchestration, Scheduling, and Cluster Management DGX OS / Ubuntu – Operating System | NVIDIA AI Enterprise – Optimized AI Software NVIDIA Base Command – Orchestration, Scheduling, and Cluster Management DGX OS / Ubuntu – Operating System |
| Rack Units (RU) | 10 RU | 10 RU | 8 RU | 8 RU |
| System Dimensions | TBA | HxWxL (444mm x 482mm x 897mm) | HxWxL (356mm x 482mm x 897mm) | HxWxL (356mm x 482mm x 897mm) |
| Operating Temperature | 5–35°C (41–95°F) | 5–30°C (41–86°F) | 5–30°C (41–86°F) | 5–30°C (41–86°F) |
| Enterprise Support | Three-year Enterprise Business-Standard Support for hardware and software 24/7 Enterprise Support portal access | Three-year Enterprise Business-Standard Support for hardware and software 24/7 Enterprise Support portal access | Three-year Enterprise Business-Standard Support for hardware and software 24/7 Enterprise Support portal access | Three-year Enterprise Business-Standard Support for hardware and software 24/7 Enterprise Support portal access |
| Datenblatt | Datenblatt | Datenblatt | Datenblatt |



Leistung der nächsten Generation
Skalierung von KI-Fabriken auf ein beispielloses Niveau
Skalierung von KI-Fabriken auf ein beispielloses Niveau
Erleben Sie KI-Reasoning-Leistung auf einem neuen Niveau mit der NVIDIA GB300 NVL72 Plattform. Im Vergleich zu Hopper bietet die GB300 NVL72 eine beeindruckende 10-fache Verbesserung der Benutzerreaktionsfähigkeit (TPS pro Benutzer) und eine 5-fache Verbesserung des Durchsatzes (TPS pro Megawatt (MW)). Zusammen führen diese Fortschritte zu einem bemerkenswerten 50-fachen Sprung der Gesamtleistung für KI-Fabriken.
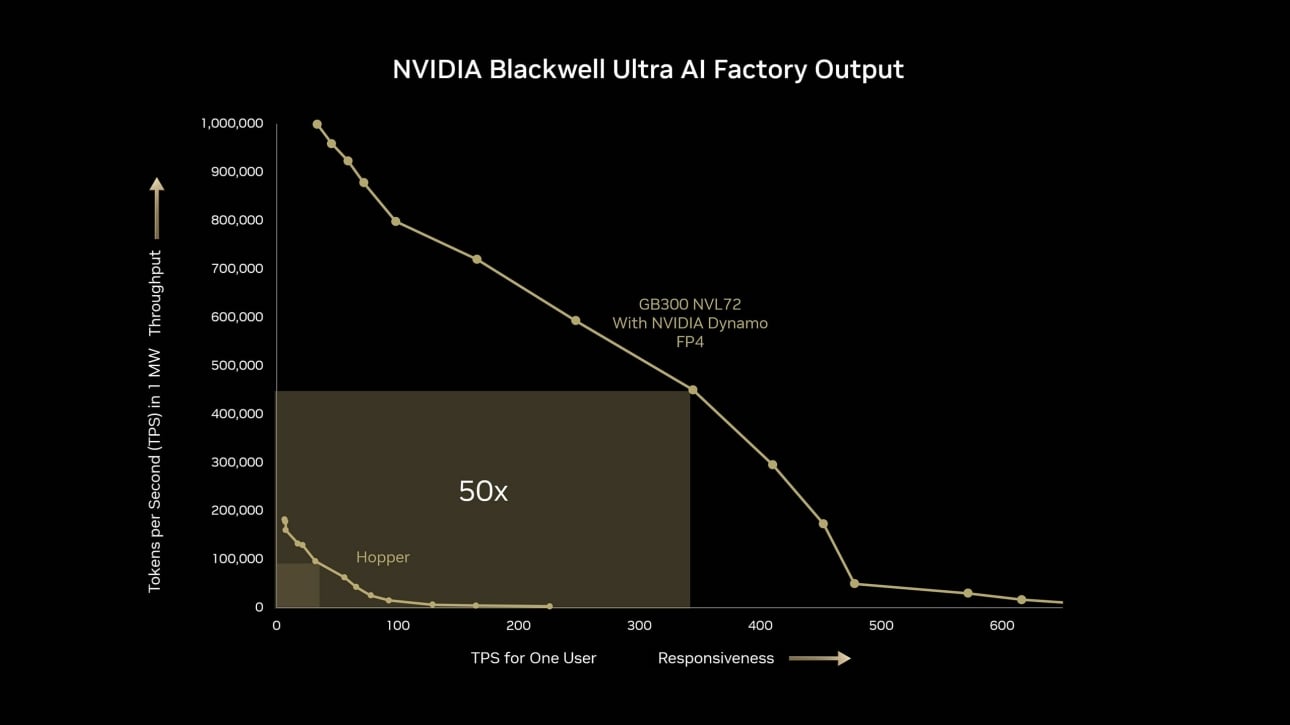
DeepSeek R1 ISL = 32K, OSL = 8K, GB300 NVL72 mit FP4 Dynamo Disaggregation. H100 mit FP8 In-Flight-Batching. Die projizierte Leistung kann Änderungen unterliegen.
Vom einzelnen Server zum NVIDIA DGX B300 BasePOD oder B300 SuperPOD
Oder alternativ gleich zu der DGX GB300 NVL72
DGX B300 Systeme können mit InfiniBand geclustert werden und ermöglichen dadurch effizientes Multi-GPU-Computing. Man spricht dann von einem DGX B300 BasePOD oder DGX B300 SuperPOD.
Große Sprachmodelle und viele weitere Anwendungen profitieren stark von der extrem schnellen Vernetzung der GPUs. Bei der DGX GB300 NVL72 sind 72 B300 GPUs mit NVLink geclustert, als wäre es eine einzige GPU.
NVIDIA DGX SuperPOD™ mit DGX B300 und GB300 NVL72 Systemen bietet führenden Unternehmen die Möglichkeit, eine große, schlüsselfertige Infrastruktur bereitzustellen, die sich auf die KI-Expertise von NVIDIA stützt.
Haben Sie Fragen zu der NVIDIA DGX B200 oder B300, helfen oder geben wir Ihnen dazu gerne eine Auskunft. Gerne können Sie auch den Live Chat Button rechts unten auf der Webseite nutzen.
Kontakt: Tel: +49 40 300672 - 0 | Fax: +49 40 300672 - 11 | E-Mail: info[at]delta.de
